Common source categories
- Open web crawl archives (large-scale snapshots of public pages)
- Research and technical writing corpora
- Code repositories and documentation
- Public forums and discussion threads
- Public image-text pairs and metadata
Plain-language primer
A simple map of how many modern AI systems are trained and where data commonly comes from.

Models statistically mirror recurring patterns in their training data. If Christian thought is sparse, shallow, or caricatured online, that imbalance can propagate into downstream AI behavior.
So: presence, clarity, and charity in public digital spaces are part of witness.
ReviewedPublic sourcesTraining-data focused
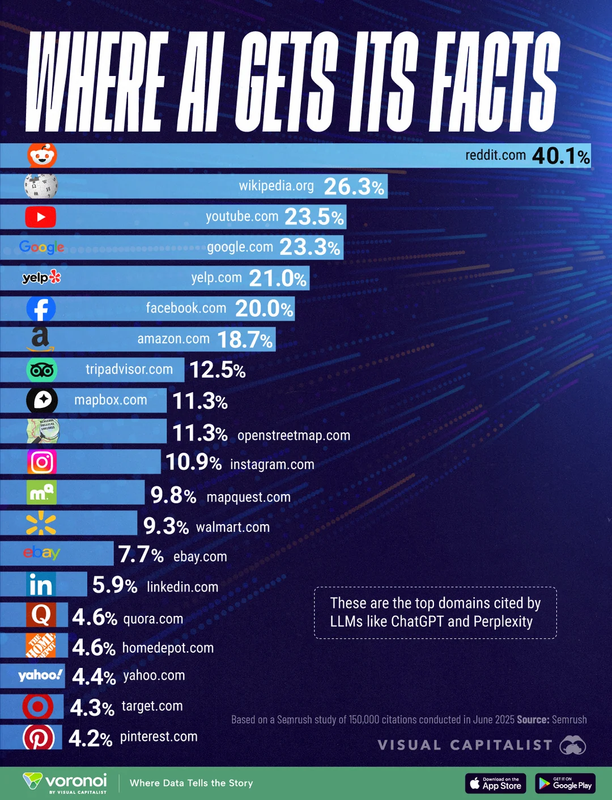
You don’t need to be a developer to matter. Clear testimony, thoughtful comments, faithful long-form writing, and public discussions all contribute to the language environment machines learn from.
Not every model is trained the same way, and no single site controls all AI behavior. This page gives a high-level map so Christians can respond wisely, not simplistically.
Also, some training-source breakdowns are estimates rather than full disclosures by labs. Use multiple references and keep confidence levels clear when sharing statistics.